Crafting A Lox Interpreter In Rust, Part 1
Posted on February 3, 2022 • 13 minutes • 2661 words
TL;DR: I’m making an interpreter in Rust for Lox, a scripting language. Here I’m showing what I learned so far. Source code: https://github.com/diegofreijo/rlox-vm
On my latest holidays, I read the amazing book Crafting Interpreters by Robert Nystrom. There he teaches how to write from scratch an interpreter. In fact, it shows how to do two of them:
- A tree-walk interpreter written in Java, called
jlox. - A bytecode virtual machine written in C, called
clox.
The implemented language is Lox, a dynamically-typed scripting language created for this book. It is similar to JavaScript or Lua.
I’m amazed by how simply he managed to explain so many complex concepts. And the fact that the book is very pragmatic allows him not to spend too much time in theory that won’t serve any purpose. Instead, he explains just the necessary bits of information that would allow him to explain the code written. If you want to make your own language, or you are just curious about how an interpreter works from scratch, I strongly recommend you this book. Oh, and it’s free.
🦀 rlox-vm
I’ve toyed around with parsers and interpreters in the past. But I never implemented a fully-working one from scratch. So I wanted to follow along with the book and write my own interpreter.
I’ve been also looking forward to some time now to learn Rust. So these two objectives seemed to align pretty well.
Oh and also I wanted to kickstart a (new) blog where I can share these kinds of experiences. So that’s 3 objectives I’m tackling with just one project. A deal.
I chose to write the virtual machine version of the interpreter (clox) because it’s made in C. And I found Rust much closer to C than Java. Also, it’s more performant than jlox. And so I decided to write rlox-vm. I’m a genius at naming things.
The implementation I have so far is not complete. I finished chapter 25, which means that I have a language that can do function declarations with control structures, variables, and expressions. I’m still missing classes and garbage collection. Plus some potential refactoring I’ll make after I’m done with the book. But I needed to start writing down the ideas in my head before I start forgetting them.
So in this post, you’ll find the interesting implementation details I found along the way while both learning how to use Rust and how to make an interpreter.
The source code can be found on Github: https://github.com/diegofreijo/rlox-vm .
Data Structures And Memory Handling
I like that the book shows you how to create a basic vector, a stack, a linked list, and some other small data structures. We usually take these for granted in higher-level languages than C or just by using the standard library. By manually writing those you get not to depend on any of the implementations from the hosting language. And you get to manage every byte you use on the stack or the heap. So you are forced to learn those details.
I already had to write those data structures when I was in college. And it’s not something I was looking forward to re-learn how to do in Rust. Besides, I did want to learn how to use Rust’s standard library. So for now I did not implement these low-level structures.
The same can be said for memory management. I did not reach the garbage collection part yet, but still, I just opted to rely on Rust’s memory management mechanisms. This is one of the hardest areas to get used to while learning this language, so I just wanted to bite the bullet and go ahead with it. Maybe in the future I’ll implement my own homemade garbage collection.
🔍 Scanner
The scanner is responsible for converting boring characters into fancy Tokens. These can be easily handled by the Compiler later on in the interpretation chain.
pub struct Scanner<'a> {
source: &'a String,
chars: PeekMoreIterator<Chars<'a>>,
start: usize,
current: usize,
line: i32,
}
I Demand Tokens
As implemented by the book, this Scanner also works on an on-demand basis. So it won’t scan for Tokens until somebody asks for one. The core function is scan_token:
pub fn scan_token(&mut self) -> TokenResult<'a> {
self.skip_whitespaces();
self.start = self.current;
match self.advance() {
Some(c) => match c {
_ if Scanner::is_alpha(c) => self.identifier(),
_ if Scanner::is_digit(c) => self.number(),
// Single-char tokens
'(' => self.make_token(TokenType::LeftParen),
')' => self.make_token(TokenType::RightParen),
// (...)
'<' => self.make_token_if_matches(&'=', TokenType::LessEqual, TokenType::Less),
'>' => {
self.make_token_if_matches(&'=', TokenType::GreaterEqual, TokenType::Greater)
}
// String literals
'"' => self.string(),
// Error
_ => self.token_error(&format!("Unexpected character '{}'", c)),
},
None => self.make_eof(),
}
}
The function is just a big switch (well, match in Rust parlance). As Bob would say “a switch with delusions of grandeur”. It’s simple but it works, so I love it.
Token Result Not Always Results In A Token
The Token is a simple structure, pretty much like what is described in the book.
#[derive(Clone, Debug)]
pub struct TokenResult<'a> {
pub line: i32,
pub token_type: TokenType,
pub data: Result<Token<'a>, String>,
}
impl<'a> TokenResult<'a> {
pub fn invalid() -> Self {
TokenResult{ line: -1, token_type: TokenType::Error, data: Err(String::from("Invalid")) }
}
}
#[derive(Clone, Debug)]
pub struct Token<'a> {
pub start: usize,
pub end: usize,
pub lexeme: &'a str,
}
Still, the scanner can find an unexpected character, so the advance method needs some kind of failure result. I could have made it return Option<Token> or Result<Token, String>, but I wanted to keep the code as close as possible to the book. So I had to use a TokenType::Error to signal that there was an error. And that forced me to emit a Token even when an error happened.
Looking now in hindsight I would just go with the Result<Token, String>. That would provide a better error handling experience both from the Scanner side and from the Compiler one, plus the safeties added by Rust’s compiler. Maybe in the future I’ll refactor it.
State Assumptions
A little critique I have to make to the book is how it delegates the responsibilities to the Scanner methods. And how the state is assuming among them.
Let’s take a look for example at how strings are scanned. The function above first looks for a ". If it finds one, it moves the rest of the matching to the string method.
fn string(&mut self) -> TokenResult<'a> {
// I already consumed the initial " before. I'm storing as a lexeme the string
// with no "s
self.start += 1;
while !self.peek_matches(&'"') && !self.is_eof() {
if self.peek_matches(&'\n') {
self.line += 1;
}
self.advance();
}
if self.is_eof() {
self.token_error(&format!("Unterminated string. Token so far: {:?}", self.make_token(TokenType::String)))
} else {
let ret = self.make_token(TokenType::String);
self.advance();
ret
}
}
This method has to assume that the first " that makes up a string literal was already consumed. So it has to move the start position forward. I had to add a comment for my future self to understand why I did that. But after the value is consumed this same function consumes the second ".
I would like it if the same method were responsible for consuming both characters. This kind of implementation hides state assumptions that make it harder to read for newcomers to the project. And it is a bit error-prone if for some reason this method was called from someplace else where this state assumption was not met.
Peek Next
The biggest technical complexity I found here was how to implement the second look-ahead. In other words, the peek_next function. At first, I was just using the Chars struct, which is returned by the chars() method implemented in String. This struct provides an iterator for easy access to each character on the string.
/// An iterator over the [`char`]s of a string slice.
///
///
/// This struct is created by the [`chars`] method on [`str`].
/// See its documentation for more.
///
/// [`char`]: prim@char
/// [`chars`]: str::chars
#[derive(Clone)]
#[stable(feature = "rust1", since = "1.0.0")]
pub struct Chars<'a> {
pub(super) iter: slice::Iter<'a, u8>,
}
Iterators provide a peek method that allows one-character lookahead. But I found no easy way to peek at the next one. The only solutions I was getting were on the sort of removing a character, peeking, and adding it back. Pretty inefficient.
That’s why I ended up using the PeekMore crate. It wraps an iterator that would allow you to peek at as many lookaheads as needed. I would like to revisit this implementation and maybe add one on my own, as I’m already reinventing many wheels. But for now, it works.
💡 Compiler
The Compiler takes the tokens created by the Scanner and produces a Chunk, which is just a list of Operations that will be run afterward by the Virtual Machine.
pub struct Compiler<'a> {
pub had_error: bool,
panic_mode: bool,
scanner: Scanner<'a>,
previous: TokenResult<'a>,
current: TokenResult<'a>,
locals: Vec<Local>,
scope_depth: i8,
}
This part was a beast. And I’m not done with it yet. I never realized how much a compiler does until now. And I didn’t implement any complex static analysis here including type-checking.
Precedence Table
I found this algorithm quite interesting. And hard to understand at first. It’s one of those things you finish understanding after you wrote it and used it.
On rlox-vm I used a better way to encode a big table. I just used a match clause. I’m not sure how Rust’s compiler converts it to binary, but I would bet that it’s at least as performant as a lookup on a C array. And has better safety measures implemented by the compiler as match clauses force the developer to write every possible case.
Functions And Closures
The main method of this struct is … 🥁 drum roll 🥁 … compile.
pub fn compile(&mut self) -> ObjFunction {
let mut frame = ObjFunction::new("main");
self.advance();
while !self.matches(TokenType::Eof) {
self.declaration(&mut frame);
}
self.emit_return(&mut frame);
#[cfg(feature = "debug_print_code")]
if !ret.had_error {
ret.chunk.disassemble("code");
}
frame
}
It just returns a function. As the book proposed, I’m considering the global scope as the main function that happens to define other functions that get called afterward.
I used to have a relatively clean Compiler implementation when there was no other function in scope. Life was easy: I was just identifying expressions, adding operations to the only function under compilation, and then just giving it to the Virtual Machine to bring it to life.
But now, after adding the possibility for defining functions (or closures) I was not sure anymore where should I add to the newly-compiled operations. I did not want to rely on the global state, as opposed to the book. And I had some borrow issues when adding a reference to the current frame on the Compiler state.
So I went with the more functional way to pass around stuff: add it as a parameter to every function that needs to write operations. The result was somewhat messy and probably there is a better way, like by solving the borrowing issues I described. But for now, it works.
So now every method uses and passes around the current frame (the ObjFunction) to the other methods. The only difference is the function (Compiler’s method) that compiles a function (defined in Lox by the user) because it creates a new function (ObjFunction which is the value representing a list of operations that the Virtual Machine knows how to run) that passes to the compile function to kickstart the new declaration.
⚙️ Virtual Machine
When I read Virtual Machine I used to think about a very complex piece of software. It turns out the one I implemented ended up being pretty simple. And short, compared to the Compiler.
pub struct VM {
stack: Stack,
globals: HashMap<IdentifierName, Value>,
call_stack: Vec<String>,
}
The Machine Runs
The main VM method, run, is a loop that keeps matching for the current Operation. Once it knows what operation it should run, it just executes it using Rust’s code. Nothing too fancy.
fn run<W: Write>(&mut self, function: &ObjFunction, output: &mut W) -> InterpretResult<()> {
// (...)
match op {
Operation::Constant(iid) => {
let c = chunk.read_constant(*iid);
self.stack.push(c.clone());
}
Operation::Nil => self.stack.push(Value::Nil),
Operation::True => self.stack.push(Value::Boolean(true)),
Operation::False => self.stack.push(Value::Boolean(false)),
// (...)
Global And Local Variables
The book proposes two different ways to implement variables, depending on if they are a global variable (defined outside of a function) or a local one (defined in a function, including parameters).
For the globals, it implements a map data structure implemented over a trie. A pretty interesting implementation. On my end, instead, I just went with a simple Rust hash map. For the locals, they are pushed on the stack for faster access.
It’s great that we had the chance to see two different kinds of implementations. But if I were creating another interpreter from scratch I would try to use a single way to manage them. Managing to push them all into the stack would be great for performance reasons, but of course, it has its limitations. Some pointers to heap areas would still need to exist for variable-length values like strings. At least there would not be two different ways to access values.
⚠️ Error Reporting
Compile and runtime errors are poorly handled as it is on rlox-vm. I wrote some of the artifacts needed to properly report errors, like the line number for a code at the Compiler or the call_stack at the VM. But I’m barely using them as for now I’m not expecting people to use this interpreter beside me.
I agree with Bob when he wrote that a good language implementation needs good error handling and reporting. From what I see, that’s what is helping people adopt a strict compiler like the one in Rust. The same was seen in languages like Elm , where people enjoy the development experience just because of how good the error messages are.
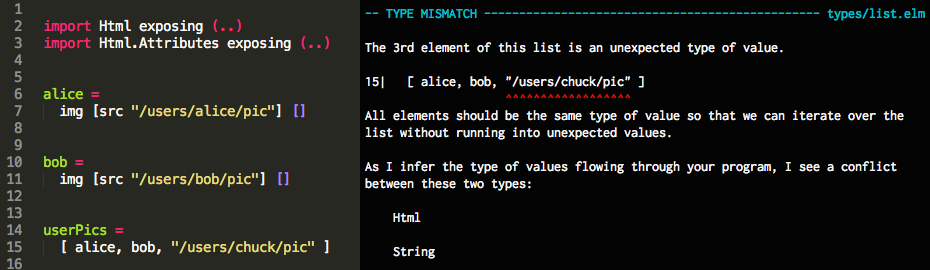
Elm's error handling
✅ Testing
Another big reason why I did not write a super helpful error reporting framework was that I did not need it. And that’s because I wrote several tests for the most complex pieces of logic. The main one is the compiler.
The whole testing experience was very pleasant for me. Adding also Rust’s strict compiler made me pretty confident that if the code compiled and the tests were passing then it would work 99% of the time.
So every time I was having an issue with the interpreter I would just write a unit test for that piece of logic and fix the code until the tests pass. I did not try to implement some sort of TDD as I was following the code from the book. On the other hand, if I were to write a new project from scratch I would probably do so.
By the way, you can keep the tests running on watch mode by using the cargo-watch crate. And then running:
cargo watch -x "test"
Or watching individual tests while you’re trying to make it work:
cargo watch -x "test compiler::tests::recursive_functions"
📚 Resources
It turns out, unsurprisingly, that I’m not the only one that decided to implement the Lox interpreter described in the book. Some folks also implemented it in Rust, and others even wrote it in Lox itself. That’s mind-blowing. Check out the
official list of Lox implementations
if you’re curious about how they did that. I hope that soon you’ll see rlox-vm there!
One of the Rust implementations that I liked is called rlox and its author
wrote a post
describing it. I took a look at its code and stole got inspired by some of his ideas that I later on added to rlox-vm.
⏭️ Next Steps
I’m looking forward to:
- Implement the remaining
cloxfeatures like classes and garbage collection. - Improve error reporting.
- Refactor the codebase to make it less imperative and more functional.
Or maybe I get too deep into the language hacking world and end up making a whole new language just for fun and no profits. 😃